
LLMs in Self-Driving Cars: Teaching Machines to Understand the Road Like Humans
- Nagesh Singh Chauhan
- Jan 1
- 10 min read

How LLMs bring reasoning, context, and human understanding to the heart of autonomous driving.

Introduction
The concept of self-driving cars has evolved far beyond mere cruise control or adaptive speed systems. Today’s autonomous vehicles (AVs) depend on a multilayered architecture of sensors, machine learning models, and decision-making algorithms to interpret their environment and move safely. Until recently, autonomous driving systems were dominated by perception and control modules — but with the rise of large language models (LLMs), a powerful new paradigm is emerging where language-based reasoning and contextual understanding become core components of self-driving systems.
In this blog, we explore how LLMs can transform self-driving cars — from improving decision reasoning and human-AI interaction to bridging gaps between structured sensor data and unstructured real-world context.
The Autonomous Driving Stack: A Quick Overview
Before understanding where Large Language Models (LLMs add value), it’s important to first examine how a typical autonomous vehicle (AV) is structured today. Modern AV systems are built as a layered software stack, with each layer responsible for a specific function in the driving pipeline.

The 4 Pillars of Self-Driving Cars are Perception, Localization, Planning, and Control. Credits
Perception
Perception is the vehicle’s sensory system.
Inputs: Cameras, LiDAR, radar, and ultrasonic sensors
Responsibility: Detect, classify, and track objects such as vehicles, pedestrians, cyclists, lane markings, and obstacles
Output: A structured, semantic representation of the surrounding environment
This layer answers the question: What is happening around the vehicle right now?
Localization and Mapping
This layer determines where the vehicle is in the world.
Combines sensor data with high-definition maps
Estimates the vehicle’s precise position and orientation relative to lanes, landmarks, and road geometry
It answers: Where am I, relative to the road and surroundings?
Prediction
Prediction focuses on understanding how the environment may evolve.
Forecasts the future trajectories of nearby agents
Estimates intent and motion of vehicles, pedestrians, and cyclists
This layer answers: What is likely to happen next?
Planning and Control
Planning and control convert understanding into action.
Planning: Determines a safe and efficient trajectory from the current state to the desired goal
Control: Executes that trajectory through steering, braking, and acceleration
This layer answers: What should the vehicle do, and how should it do it?
This architecture relies heavily on deep learning for perception and classic planners for trajectory control. However, reasoning about contextual knowledge — like interpreting ambiguous road scenarios, obeying nuanced traffic norms, and understanding natural language instructions — is still limited.
What Problems Can LLMs Solve in Autonomous Driving?
Large Language Models (LLMs) are not designed to replace the core, safety-critical components of autonomous vehicles such as low-level control, sensor fusion, or real-time actuation. Instead, they address a different class of problems—those rooted in reasoning, semantics, abstraction, and human alignment. When viewed through this lens, LLMs solve some of the hardest unsolved challenges in autonomous driving that traditional machine learning struggles with.
Below is an elegant, unified explanation of what problems LLMs are uniquely positioned to solve, synthesized from the entire discussion and research context
1. Bridging the Gap Between Perception and Understanding

Traditional perception systems excel at detecting objects—cars, lanes, pedestrians—but they lack semantic understanding. They answer “what is there?”, not “what does it mean?”.
LLMs address this gap by:
Interpreting scenes at a semantic level
Reasoning about intent, context, and uncertainty
Explaining situations in human-like terms
For example, rather than just detecting a pedestrian, an LLM-augmented system can reason that:
“The pedestrian’s speed and trajectory suggest they may enter the crosswalk.”
This transforms perception outputs into actionable understanding, especially in ambiguous or edge-case scenarios.
Other models such as HiLM-D and MTD-GPT can also do this, some work also for videos. Models like PromptTrack, also have the ability to assign unique IDs (this car in front of me is ID #3), similar to a 4D Perception model.

PromptTrack combines the DETR object detector with Large Language Models. Credits
In this model, multi-view images are sent to an Encoder-Decoder network that is trained to predict annotations of objects such as bounding boxes, and attention maps). These maps are then combined with a prompt like 'find the vehicles that are turning right'.The next block then finds the 3D Bounding Box localization and assigns IDs using a bipartite graph matching algorithm like the Hungarian Algorithm.
2. High-Level Decision Making and Planning Under Ambiguity
If Chat-GPT can find objects in an image, it should be able to tell you what to do with these objects, shouldn't it? Well, this is the task of Planning i.e. defining a path from A to B, based on the current perception. While there are numerous models developed for this task, the one that stood out to me was Talk2BEV:
Talk2BEV takes perception one step further and also tells you what to do. Credits
The main difference between models for planning and Perception-only models is that here, we're going to train the model on human behavior to suggest ideal driving decisions. We're also going to change the input from multi-view to Bird Eye View since it is much easier to understand.
This model works both with LLaVA and ChatGPT4, and here is a demo of the architecture:

Talk2BEV. Credits
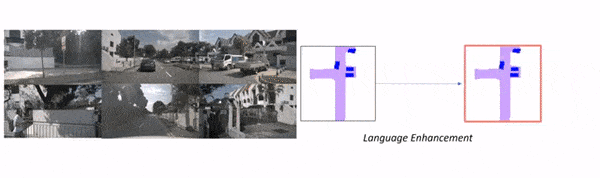
As you can see, this isn't purely "prompt" based, because the core object detection model stays Bird Eye View Perception, but the LLM is used to "enhance" that output by suggesting to crop some regions, look at specific places, and predict a path. We're talking about "language enhanced BEV Maps".
Other models like DriveGPT are trained to send the output of Perception to Chat-GPT and finetune it to output the driving trajectory directly.

The DriveGPT model is pure madness... when trained correctly! (modified from source)
If we summarize, I would say that:
Inputs are either tokenized images or outputs of Perception algorithm (BEV maps, ...)
We fuse existing models (BEV Perception, Bipartite Matching, ...) with language prompts (find the moving cars)
Changing the task is mainly about changing the data, loss function, and careful finetuning.
3. Natural Language Interaction and Intent Translation
One of the clearest problems LLMs solve is human–vehicle communication.
Humans think and communicate in language, not waypoints or cost functions. LLMs translate natural language intent into structured constraints that planning systems can execute.
Examples include:
“Drop me off at the entrance with the least walking distance.”
“Avoid left turns if possible.”
“Find a charging station that serves coffee.”
This eliminates rigid, pre-programmed interfaces and enables:
Personalization
Accessibility
Intuitive control
In short, LLMs solve the problem of making autonomous vehicles usable by humans.
4. Reasoning in Noisy, Incomplete, or Contradictory Situations
Autonomous vehicles operate in the real world—where sensor data is often imperfect.
LLMs excel at:
Reasoning under uncertainty
Combining weak signals into coherent interpretations
Leveraging prior knowledge and context
Examples include:
Interpreting human gestures from construction workers
Inferring emergency vehicles from partial audio or visual cues
Acting cautiously when sensor confidence is low
This makes LLMs invaluable for edge cases, where rule-based logic and statistical models often fail.
5. Encoding Traffic Laws, Norms, and Ethical Constraints

Driving is governed by textual knowledge:
Traffic laws
Regional driving norms
Ethical expectations
These are difficult to encode numerically but natural for LLMs to understand and apply.
LLMs solve the problem of:
Adapting vehicles across countries and regions
Interpreting nuanced or conflicting regulations
Applying ethical reasoning consistently
This provides autonomous systems with world knowledge that traditional ML models typically lack.
6. Explainability, Transparency, and Trust
One of the biggest barriers to large-scale AV adoption is trust.
LLMs enable vehicles to:
Explain why a decision was made
Answer questions from passengers, operators, and regulators
Support debugging, auditing, and compliance
For example:
“I reduced speed because the pedestrian’s trajectory suggests a possible crossing.”
This transforms autonomous vehicles from opaque systems into explainable, cooperative agents, addressing a critical societal and regulatory challenge.
7.LLMs for Image and Scenario Generation
If you’ve experimented with tools like Midjourney or DALL·E, you’ve already seen how powerful generative models can be. But when it comes to autonomous driving, the capabilities go far beyond creating static images—they extend into generating entire driving scenarios and videos.

These videos are generated by Wayve's GAIA-1 model
A standout example is GAIA-1, developed by Wayve. GAIA-1 takes text prompts and images as input and directly generates realistic driving videos. At the core of its architecture lies a world model—a learned representation of how the environment behaves and how actions influence future states. By conditioning on images, actions, and language, the model can simulate plausible future driving situations with remarkable fidelity.

Architecture of GAIA-1. Credits
Wayve has showcased multiple such examples through public demos and technical posts, highlighting how generative world models can capture the dynamics of real-world driving.

MagicDrive. Credits
Similarly, MagicDrive approaches generation from a perception-first perspective. Instead of raw text or images, it uses the output of perception systems—such as detected objects and scene layouts—to synthesize coherent driving scenes.
Other approaches, including Driving Into the Future and Driving Diffusion, push this idea even further by directly generating future scenarios conditioned on the current scene. These models can imagine what might happen next—lane changes, pedestrian crossings, or emerging hazards—without explicitly simulating physics step by step.
8. Data Generation and World Modeling at Scale
Finally, LLMs—combined with diffusion and world models—solve the problem of data scarcity.
Through scenario generation, future simulation, and rare-event synthesis, LLM-driven systems can:
Generate diverse training data
Simulate dangerous or rare edge cases
Create a continuous learning loop
This accelerates development while improving robustness.
In essence, LLMs solve problems of meaning, intent, reasoning, and communication—not control or perception accuracy.
They act as a semantic and cognitive layer within the autonomous vehicle architecture, bridging:
Sensors ↔ Understanding
Machines ↔ Humans
Rules ↔ Real-world complexity
They do not drive the car—but they increasingly determine how the car understands the world, interacts with people, and justifies its decisions.
As autonomous systems mature, these problems will matter as much as—if not more than—raw perception accuracy, making LLMs a foundational component of the future AV stack.
LLM + Perception Integration: The Hybrid Pipeline
LLMs don’t replace perception models — they augment them.
Multimodal Fusion

A multimodal LLM interprets road context and guides safe autonomous driving.
Modern research is focusing on vision + language models:
Textual instructions + camera feed
Sensor point clouds + semantic descriptions
Road maps + reasoned guidance
This fusion enables high-level planning informed by both geometry and semantics.
Example Flow
Sensor captures a traffic cone ahead.
Perception labels it as a “cone.”
LLM contextualizes: “Cone indicates construction; adjust speed and expect lane change.”
Planner executes a smooth trajectory shift.
Real-World Use Cases of LLMs in Autonomous Driving
Use Case 1 — Urban Driving & Human-Centric Reasoning
Urban environments are dense, unpredictable, and heavily influenced by human behavior. LLMs help autonomous vehicles interpret subtle cues such as:
Crosswalk semantics and pedestrian intent
Non-verbal signals from traffic officers, construction workers, or pedestrians
Implicit right-of-way scenarios not explicitly marked by signage
By reasoning beyond raw sensor data, LLMs enable safer and more human-aligned behavior in complex city driving conditions.
Use Case 2 — Natural Voice Commands from Passengers
Passengers interact with autonomous vehicles in natural language, not technical constraints.
For example:
“Take the scenic route, but avoid potholes.”
The LLM interprets this as a multi-objective request—balancing comfort, aesthetics, and road quality—and translates it into structured constraints for the planning system to execute.
Use Case 3 — Handling Unexpected or Ambiguous Events
No perception system is perfect. Objects may be misclassified, partially observed, or entirely novel.
In such cases, LLMs apply semantic reasoning and logic to:
Flag uncertainty
Trigger conservative behavior
Escalate decisions to a human operator when necessary
This provides a critical safety net, ensuring the vehicle reacts cautiously rather than confidently incorrect.
Could We Trust LLMs in Self-Driving Cars?
Yes—but with clear limits and strong guardrails.
LLMs should not be trusted to directly control steering, braking, or acceleration. Those safety-critical tasks must remain with deterministic planners and control systems. Where LLMs can be trusted is in high-level reasoning and communication.

Trust in autonomous driving isn’t about handing control to LLMs—it’s about using them as cognitive copilots. LLMs interpret intent, reason through ambiguity, and explain decisions, while safety-critical control remains firmly guarded by validated planners and systems.
They are valuable for:
Interpreting ambiguous situations (human gestures, construction zones)
Understanding passenger intent in natural language
Applying traffic rules and regional norms
Explaining decisions in human-readable terms
Trust in LLMs is architectural, not blind. Their outputs are validated by safety rules, constrained by planners, and overridden when uncertainty is high.
Bottom line: LLMs are best used as cognitive copilots—helping autonomous cars understand, explain, and align with humans, without ever taking direct control of the vehicle.
Dealing with Hallucinations in LLMs for Self-Driving Cars
Hallucinations—when LLMs produce confident but incorrect outputs—pose a critical risk in self-driving cars, where decisions must be precise, real-time, and safety-guaranteed. Unlike consumer applications, autonomous vehicles cannot afford fabricated assumptions about traffic laws, road conditions, or right-of-way. Even a single hallucinated inference can propagate into unsafe driving behavior with real-world consequences.

Hallucination reduction model framework. Credits
To mitigate this, automotive LLMs are tightly constrained, grounded, and supervised. They are fine-tuned on curated, domain-specific driving data with strong guardrails that restrict unsafe reasoning. Techniques such as reinforcement learning from human feedback (RLHF) and multimodal grounding—combining vision, language, and action—further reduce hallucinations by anchoring decisions in real-world perception.
Models like Lingo-1 exemplify this approach, cross-validating language-based reasoning with visual input and vehicle actions to learn causal relationships and operate reliably within trusted safety boundaries.
LINGO-1: Natural Language for Smarter, More Explainable Driving
One of the exciting advances at the intersection of LLMs and autonomous driving is LINGO-1, a vision-language-action model developed by Wayve that explores how natural language can enhance driving intelligence and explainability.
Traditional self-driving models often operate as “black boxes,” making decisions that are difficult to interpret. LINGO-1 tackles this by combining vision, language, and driving actions into a unified model that can not only understand scenes but also comment on them and explain driving decisions in natural language.
At its core, LINGO-1 is trained on a rich dataset that pairs images, driving actions, and human commentary—collected from expert drivers narrating what they see and why they act—as they drive. This effectively teaches the model to associate visual context with human-like explanations of driving behavior.
What LINGO-1 Enables
Driving Commentary: LINGO-1 can generate continuous language explanations about driving actions (e.g., describing why it slowed, stopped, or accelerated).
Visual Question Answering: Users can query the model about specific aspects of a scene—what it sees, how it interprets it, and what factors influenced its choices.
Improved Transparency: By grounding language in visual attention and decision context, LINGO-1 offers a window into how autonomous systems reason about the world, helping build trust and understanding.
Why It Matters
LINGO-1’s integration of language with perception and action opens the door to more interpretable, flexible, and communicative autonomous driving systems. Rather than just making decisions, the vehicle can explain them—making it easier for developers to diagnose behavior, for regulators to audit systems, and for passengers to trust the technology.
Conclusion
Large Language Models are poised to become a major catalyst in the evolution of self-driving cars.They don't replace the core perception and control systems — but they bring semantics, reasoning, and explainability to an industry hungry for context-aware intelligence.
From richer human-AI interactions to safer contextual decisions, LLMs add a layer of cognitive comprehension once thought exclusive to human drivers. The journey towards fully autonomous vehicles won’t be complete until machines can not only see and navigate — but also understand the world around them.



Comments