
Top 23 types of RAG Architectures
- Nagesh Singh Chauhan
- Dec 28, 2025
- 31 min read

A practical guide to the most important RAG architectures—explained clearly, compared simply, and ready to apply in real-world LLM systems.

Introduction
Large Language Models (LLMs) are powerful, but they are fundamentally constrained by static training data, limited context windows, and a tendency to hallucinate when knowledge is missing or outdated. Retrieval-Augmented Generation (RAG) emerged as the most practical solution to these limitations—by grounding generation in external, up-to-date, and verifiable knowledge.
What started as a simple “retrieve documents → stuff them into the prompt → generate” pipeline has now evolved into a rich ecosystem of RAG architectures, each designed to optimize for different dimensions: accuracy, latency, reasoning depth, personalization, trust, or autonomy.
Today, RAG is no longer a single technique—it is a design space. In this blog, we explore the top 23 types of RAG, why they exist, and when to use each one.
1. Standard RAG
The foundational approach where a query retrieves relevant documents from a knowledge base and injects them into the prompt before generation. It improves factual accuracy but relies heavily on retrieval quality.
Why Standard RAG Exists
Large Language Models are powerful but limited:
They have a fixed knowledge cutoff
They can hallucinate facts
They cannot access private or dynamic data
Retraining is expensive and slow
Standard RAG solves this by bringing external knowledge into the model at inference time, without retraining.
How Standard RAG Works (Step-by-Step)
User Query
The user asks a question
Query Embedding
The query is converted into a vector using an embedding model
Document Retrieval
A vector database retrieves top-K similar chunks
Similarity is usually cosine or dot-product based
Context Injection
Retrieved chunks are appended to the prompt
LLM Generation
The LLM generates an answer using the provided context

An illustration of Standard RAG
Key Characteristics
Single-stage retrieval
Flat chunk structure
Similarity-based relevance
No explicit ranking or reasoning layers
Fast and simple to implement
2. Conversational RAG
Conversational RAG (Retrieval-Augmented Generation) is a RAG architecture designed for multi-turn conversations, where the system retrieves information not only based on the user’s latest question, but also on the entire conversation history and conversational state.
What Problem Does Conversational RAG Solve?
Standard RAG treats every query as isolated. In real conversations, users:
Ask follow-up questions
Refer to earlier answers (“that policy”, “the same hotel”, “what about refunds?”)
Change intent gradually
Conversational RAG maintains context continuity, ensuring retrieval and generation remain aligned with what has already been discussed.
How Conversational RAG Works (Step-by-Step)
Conversation State Tracking: The system maintains short-term memory (recent turns) and sometimes long-term memory (past sessions, preferences).
Query Reformulation: The user’s latest message is rewritten into a standalone, explicit query using the conversation context.
Example:
User: “What about late checkout?”
Rewritten query: “What is the late checkout policy for the hotel we discussed earlier?”
Context-Aware Retrieval: Retrieval uses:
Reformulated query
Conversation metadata (entity, topic, intent)
Grounded Generation: Retrieved documents + relevant conversation snippets are injected into the prompt to generate a coherent response.
State Update: The conversation memory is updated for the next turn.

An illustration on Conversational RAG
Key Characteristics
Multi-turn awareness – understands references and ellipses
History-conditioned retrieval – retrieval depends on what was previously discussed
Reduced hallucinations – avoids guessing missing context
More natural interactions – feels “human-like” and continuous
Example
Without Conversational RAG (Standard RAG):
User: “What is the cancellation policy?”
User: “And late checkout?”→ Model may retrieve generic late checkout info, missing context.
With Conversational RAG:The second question retrieves late checkout policy for the same property and booking context, producing a precise answer.
Where Conversational RAG Is Used
Customer support chatbots
Travel & booking assistants
Enterprise knowledge assistants
Legal and policy Q&A systems
Healthcare and insurance support
When You Should Use Conversational RAG
Use it when:
Users ask follow-up questions
Context spans multiple turns
Precision depends on prior answers
You want a chat-native experience
One-Line Summary
Conversational RAG enables LLMs to retrieve and reason using conversation history, making multi-turn interactions accurate, coherent, and context-aware.
3. Corrective RAG
Corrective RAG (Retrieval-Augmented Generation) is a RAG architecture designed to detect, diagnose, and correct failures in retrieval or generation before delivering a final answer.
Instead of blindly trusting retrieved documents, the system actively evaluates their quality, relevance, and consistency, and takes corrective action when needed.
What Problem Does Corrective RAG Solve?
Standard RAG systems fail in subtle but critical ways:
Retrieved documents are irrelevant or outdated
Retrieved sources contradict each other
Retrieval misses key information
The model generates an answer with low evidence support
Corrective RAG addresses this by introducing a self-check and repair loop, ensuring responses are grounded, complete, and reliable.
How Corrective RAG Works (Step-by-Step)
Initial RetrievalThe system retrieves documents using standard dense/sparse retrieval.
Evidence EvaluationA validation step evaluates:
Relevance to the query
Coverage (are key aspects missing?)
Consistency across documents
Confidence score of the answer
Error DetectionThe system detects signals such as:
Conflicting facts
Weak or partial evidence
Low semantic alignment
Corrective ActionDepending on the issue, the system may:
Reformulate the query
Retrieve from alternative sources
Increase retrieval depth
Filter or re-rank documents
Regeneration with Corrected ContextThe model regenerates the answer using improved evidence.
Final Validation (Optional)Some systems perform a final answer check before responding.
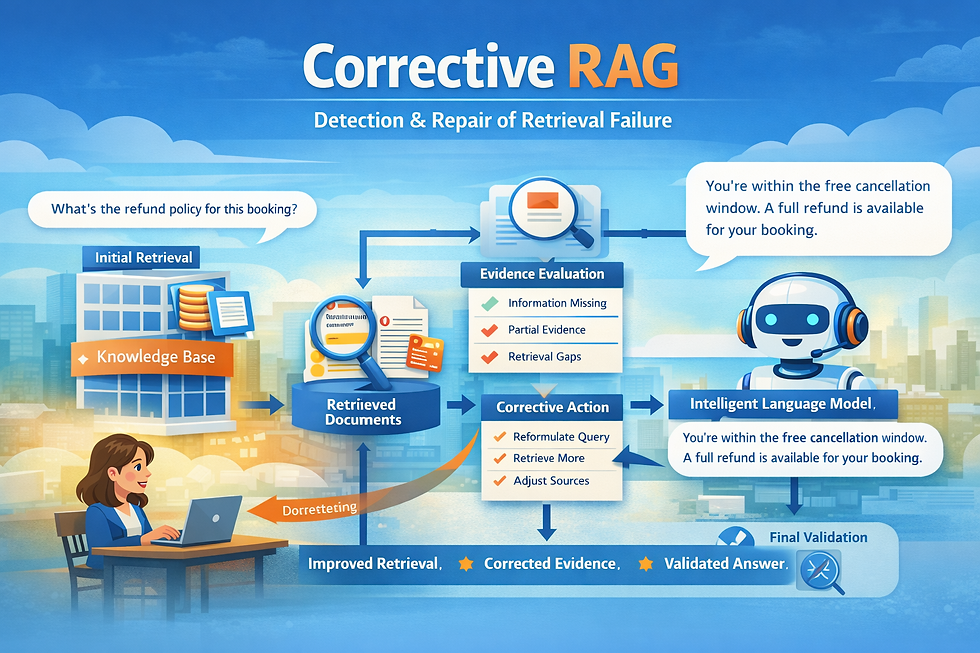
An illustration on Corrective RAG
Key Characteristics
Self-correcting retrieval loop
Evidence-aware generation
Lower hallucination rates
Improved factual consistency
Explicit uncertainty handling
Example
User:“What is the refund policy for this booking?”
Without Corrective RAG
Retrieves a generic policy
Misses booking-specific conditions
Produces an incomplete or incorrect answer
With Corrective RAG
Detects missing booking context
Re-retrieves using booking ID + channel
Resolves conflicting policy clauses
Generates a precise, policy-aligned response
Where Corrective RAG Is Used
Financial systems (pricing, refunds, invoices)
Healthcare decision support
Legal and compliance tools
Enterprise knowledge assistants
Customer support escalation workflows
When You Should Use Corrective RAG
Use Corrective RAG when:
Errors are costly or irreversible
Information may be incomplete or conflicting
Regulatory or policy accuracy is critical
Users demand high confidence answers
One-Line Summary
Corrective RAG actively detects and repairs retrieval and grounding failures, making RAG systems trustworthy in high-stakes environments.
4. Hybrid RAG
Hybrid RAG (Retrieval-Augmented Generation) is a RAG architecture that combines multiple retrieval techniques—most commonly dense (vector-based) and sparse (keyword-based) retrieval—into a single system to improve recall, precision, and robustness.
Instead of relying on one retrieval signal, Hybrid RAG leverages the strengths of different retrievers to ensure that relevant information is not missed.
What Problem Does Hybrid RAG Solve?
Single-retriever systems have clear weaknesses:
Dense retrieval
Misses exact matches, IDs, rare terms, or numbers
Sparse retrieval (BM25)
Fails on semantic or paraphrased queries
Hybrid RAG solves this by covering both semantic similarity and lexical precision, reducing blind spots in retrieval.
How Hybrid RAG Works (Step-by-Step)
Parallel RetrievalThe user query is sent to multiple retrievers, typically:
Dense vector retriever (embeddings)
Sparse keyword retriever (BM25 / inverted index)
Independent Candidate SetsEach retriever returns its own ranked list of documents.
Fusion / Re-rankingResults are combined using techniques such as:
Score normalization
Reciprocal Rank Fusion (RRF)
Learned re-rankers
Context SelectionThe most relevant documents across both retrieval modes are selected.
Grounded GenerationThe LLM generates an answer using the fused evidence set.

An illustration on Hybrid RAG
Key Characteristics
Higher recall than single-retriever RAG
Robust to query phrasing
Handles rare terms and semantic intent
Retriever-agnostic and extensible
Strong enterprise-grade default
Example
User: “Refund for Booking ID 12T5PR74?”
Dense-only RAG
May miss the exact booking ID
Retrieves generic refund policies
Sparse-only RAG
Matches booking ID
Misses nuanced policy explanations
Hybrid RAG
Sparse retrieval finds booking-specific data
Dense retrieval finds policy explanations
Combined answer is precise and complete
Where Hybrid RAG Is Used
Enterprise search platforms
Customer support systems
Legal and compliance tools
Financial and booking systems
Technical documentation search
When You Should Use Hybrid RAG
Hybrid RAG is a strong choice when:
Queries mix IDs + natural language
Data contains structured + unstructured content
Missing information is unacceptable
You want a safe default RAG architecture
In practice, Hybrid RAG is often the baseline upon which more advanced variants (Corrective, Agentic, Adaptive) are built.
One-Line Summary
Hybrid RAG combines semantic and keyword retrieval to maximize coverage, making it one of the most reliable and production-ready RAG architectures.
5. Speculative RAG
Speculative RAG (Retrieval-Augmented Generation) is a RAG architecture designed to minimize latency by allowing the language model to begin generating a response before retrieval is fully completed, and then refine, validate, or correct the output once retrieved evidence becomes available.
Instead of waiting for retrieval to finish, Speculative RAG overlaps generation and retrieval, making RAG systems significantly faster without sacrificing accuracy.
What Problem Does Speculative RAG Solve?
Traditional RAG pipelines are sequential:
Query → Retrieve → Generate
This introduces noticeable latency, especially when:
Retrieval spans multiple sources
Re-ranking is expensive
Systems operate under real-time constraints
Speculative RAG solves this by transforming the pipeline into:
Speculate → Retrieve → Validate / Correct
How Speculative RAG Works (Step-by-Step)
Initial Speculative GenerationAs soon as the query arrives, the LLM generates a draft response using:
Internal knowledge
Prior conversation context
Heuristics about likely answers
Parallel RetrievalWhile the draft is being generated, retrieval runs in parallel:
Vector search
Keyword search
API or tool calls
Evidence AlignmentRetrieved documents are compared against the speculative draft to check:
Factual alignment
Missing details
Contradictions
Correction or Confirmation
If evidence matches → response is finalized quickly
If evidence conflicts → response is corrected or partially regenerated
Final Answer DeliveryThe user receives a fast, evidence-backed response.

An illustration on Speculative RAG
Key Characteristics
Low-latency RAG
Parallel execution
Draft-first generation
Evidence-based correction
Graceful degradation when retrieval is slow
Example
User:“Can I cancel my booking tomorrow?”
Traditional RAG
Waits for policy retrieval
Then generates response
Higher latency
Speculative RAG
Immediately drafts:“Cancellation depends on your policy and booking date…”
Retrieves booking-specific policy
Confirms or corrects draft
Final answer arrives faster and accurate
Where Speculative RAG Is Used
Real-time chat assistants
Voice assistants
Customer support systems
High-traffic consumer apps
Latency-sensitive enterprise tools
When You Should Use Speculative RAG
Speculative RAG is ideal when:
Response time is critical
Retrieval is slow or variable
Most queries are predictable
Minor corrections are acceptable
User experience prioritizes speed
It is often paired with Corrective RAG to ensure safety.
One-Line Summary
Speculative RAG overlaps generation and retrieval, delivering fast responses while preserving factual grounding through post-generation correction.
6. Memory-Augmented RAG
Memory-Augmented RAG (Retrieval-Augmented Generation) is a RAG architecture that extends traditional retrieval with persistent memory, allowing the system to recall past interactions, user preferences, historical decisions, or long-term facts across sessions.
While standard RAG retrieves from external knowledge bases, Memory-Augmented RAG retrieves from two sources simultaneously:
Knowledge stores (documents, databases, APIs)
Memory stores (conversation history, user context, learned preferences)
This enables responses that are not just accurate—but personalized, consistent, and contextually continuous over time.
What Problem Does Memory-Augmented RAG Solve?
Traditional RAG systems are stateless or short-memory systems:
They forget user preferences after the session ends
They repeat questions already answered
They cannot build long-term understanding of the user
They lack continuity across days, weeks, or workflows
Memory-Augmented RAG solves this by introducing long-term memory as a first-class retrieval signal.
How Memory-Augmented RAG Works (Step-by-Step)
User InteractionThe user asks a question or performs an action.
Memory RetrievalThe system retrieves relevant memories, such as:
Past conversations
User preferences
Prior decisions
Historical outcomes
Knowledge RetrievalIn parallel, it retrieves relevant external knowledge (documents, policies, facts).
Memory + Knowledge FusionRetrieved memory and documents are merged and ranked for relevance.
Grounded GenerationThe LLM generates a response that is:
Factually grounded (knowledge)
Personally consistent (memory)
Memory UpdateNew information (confirmed preferences, decisions, outcomes) is selectively written back to memory.

An illustration on Memory-Augmented RAG
Key Characteristics
Persistent long-term memory
Personalized responses
Cross-session continuity
Reduced repetition
Adaptive over time
Example
User (Week 1): “I prefer late checkout when possible.”
User (Week 3): “Can I check out late tomorrow?”
Without Memory-Augmented RAG
Retrieves generic late checkout policy
Ignores user preference
With Memory-Augmented RAG
Retrieves late checkout policy
Recalls user’s preference for late checkout
Responds accordingly and proactively
When You Should Use Memory-Augmented RAG
Use Memory-Augmented RAG when:
Users interact repeatedly with the system
Personalization improves outcomes
Context spans days or weeks
Repeated clarification is costly
Consistency matters more than raw speed
One-Line Summary
Memory-Augmented RAG enables LLMs to remember users and past decisions, transforming RAG systems from transactional tools into personalized, evolving assistants.
7. Fusion RAG
Fusion RAG (Retrieval-Augmented Generation) is a RAG architecture that retrieves information from multiple retrievers or data sources and intelligently fuses the results into a single, high-quality context before generation.
Unlike Hybrid RAG—which combines types of retrieval (dense + sparse)—Fusion RAG focuses on combining multiple retrieval outputs, potentially from different systems, indexes, or modalities, to reduce blind spots and improve robustness.
What Problem Does Fusion RAG Solve?
Single-source or single-retriever RAG systems often fail when:
Knowledge is fragmented across systems
One retriever misses relevant content
Different sources contain partial or complementary information
Rankings vary depending on query phrasing
Fusion RAG solves this by aggregating, normalizing, and re-ranking retrieval results across multiple retrieval paths.
How Fusion RAG Works (Step-by-Step)
Query Fan-OutThe user query is sent to multiple retrievers or sources, such as:
Vector indexes
Keyword search engines
Domain-specific databases
APIs or tools
Independent RetrievalEach retriever returns its own ranked list of candidate documents.
Score NormalizationScores from different retrievers are normalized to a common scale.
Fusion StrategyResults are combined using techniques such as:
Reciprocal Rank Fusion (RRF)
Weighted score aggregation
Learned fusion models
Global Re-RankingThe fused candidate set is re-ranked to select the most relevant context.
Grounded GenerationThe LLM generates a response using the fused evidence.

An illustration on Fusion RAG
Key Characteristics
Multi-retriever robustness
Improved recall and coverage
Retriever-agnostic design
Resilient to retrieval noise
Scales well with heterogeneous data
Example
User:“What fees apply to my booking?”
Without Fusion RAG
One retriever finds pricing
Another finds policies
System answers with partial information
With Fusion RAG
Pricing retriever finds cost breakdown
Policy retriever finds refund rules
Booking system retrieves booking-specific fees
All evidence is fused into a complete answer
Where Fusion RAG Is Used
Large enterprise knowledge platforms
Federated search systems
Financial and billing assistants
Compliance and policy engines
Research and analytics tools
When You Should Use Fusion RAG
Fusion RAG is ideal when:
Knowledge lives in multiple systems
No single retriever is sufficient
High recall is critical
Answers require synthesis across domains
In practice, Fusion RAG is often layered on top of Hybrid RAG.
One-Line Summary
Fusion RAG aggregates and re-ranks results from multiple retrievers to deliver more complete, resilient, and enterprise-grade answers.
8. Context-Aware RAG
Context-Aware RAG (Retrieval-Augmented Generation) is a RAG architecture that conditions retrieval and generation on rich contextual signals beyond the user’s raw query.These signals can include user role, location, time, device, intent, application state, permissions, and environmental metadata.
In short, Context-Aware RAG answers not just “What was asked?” but “Who is asking, under what circumstances, and for what purpose?”
What Problem Does Context-Aware RAG Solve?
Standard RAG systems retrieve documents based mainly on query semantics. This often leads to:
Correct but irrelevant answers for the user’s situation
Ignoring role-based or permission-based differences
Missing time-sensitive or location-specific information
Generic responses where nuance matters
Context-Aware RAG solves this by making context a first-class retrieval input, not an afterthought.
How Context-Aware RAG Works (Step-by-Step)
Context CollectionThe system gathers contextual signals such as:
User role (admin, guest, agent)
Geography or region
Time and date
Application state (booking stage, workflow step)
Permissions and access level
Context-Enriched Query ConstructionThe original query is augmented with contextual metadata to form a richer retrieval query.
Contextual RetrievalRetrieval is filtered, boosted, or scoped based on context:
Region-specific documents
Role-allowed policies
Time-valid rules or pricing
Context-Aware RankingRetrieved documents are ranked by both semantic relevance and contextual fit.
Grounded GenerationThe LLM generates a response aligned with:
Retrieved evidence
User context
Operational constraints

An illustration on Context-Aware RAG
Key Characteristics
Situation-aware retrieval
Role- and permission-sensitive
Time- and location-aware
Reduces “technically correct but useless” answers
Improves precision without increasing retrieval size
Example
User Query:“Can I cancel this booking?”
Without Context-Aware RAG
Retrieves generic cancellation policy
Ignores region, booking stage, or user role
With Context-Aware RAG
Detects:
User is a guest
Booking is in the UK
Cancellation window closes today
Retrieves the correct regional policy
Responds with a precise, actionable answer
Where Context-Aware RAG Is Used
Travel and booking platforms
Enterprise internal tools
Policy and compliance systems
E-commerce personalization
Customer support and CRM platforms
When You Should Use Context-Aware RAG
Context-Aware RAG is ideal when:
The same question has different answers for different users
Policies vary by region or time
Permissions and access matter
Precision and correctness are more important than recall
In many production systems, Context-Aware RAG quietly delivers the biggest quality jump with minimal architectural complexity.
One-Line Summary
Context-Aware RAG grounds retrieval and generation in real-world context—ensuring answers are not just correct, but appropriate for the user’s situation.
9. Agentic RAG
Agentic RAG (Retrieval-Augmented Generation) is a RAG architecture in which autonomous agents plan, decide, retrieve, reason, and act to answer a query—rather than following a fixed retrieval → generation pipeline.
In Agentic RAG, retrieval is not a single step. It is a goal-driven process, where agents dynamically decide:
What to retrieve
When to retrieve
From which sources
Whether more retrieval is needed
What actions to take next
This transforms RAG from a static system into an adaptive, decision-making workflow.
What Problem Does Agentic RAG Solve?
Traditional RAG pipelines struggle when:
Queries are ambiguous or underspecified
Answers require multiple steps or tools
Information is distributed across systems
The system must decide, not just answer
Agentic RAG solves this by introducing planning and autonomy, allowing the system to iteratively reason, retrieve, and act until the objective is satisfied.
How Agentic RAG Works (Step-by-Step)
Goal InterpretationThe agent interprets the user’s request as a goal, not just a query.
Example: “Resolve refund eligibility for this booking”
PlanningThe agent creates a plan:
Check booking details
Retrieve cancellation policy
Verify payment status
Decide eligibility
Dynamic RetrievalThe agent performs retrieval steps as needed:
Queries knowledge bases
Calls APIs
Searches documents
Requests additional context
Reasoning & EvaluationRetrieved information is reasoned over to assess:
Completeness
Conflicts
Next actions
Iterative Loop (Optional)If gaps are detected, the agent loops back to retrieval or planning.
Action & ResponseThe agent:
Produces a grounded answer
Or triggers downstream actions (update system, notify user, escalate)

An illustration on Agentic RAG
Key Characteristics
Autonomous planning
Multi-step reasoning
Tool and API integration
Iterative retrieval loops
Goal-oriented behavior
Example
User:“Can you process my refund?”
Without Agentic RAG
Retrieves generic refund policy
Responds with partial guidance
With Agentic RAG
The agent:
Retrieves booking details
Checks payment status
Retrieves cancellation policy
Evaluates eligibility
Confirms refund amount
Responds with a definitive outcome or next action
Where Agentic RAG Is Used
Enterprise workflow automation
Financial operations (refunds, billing, audits)
Research and analysis agents
Customer support resolution systems
AI copilots with tool access
When You Should Use Agentic RAG
Agentic RAG is ideal when:
Tasks require decision-making
Answers depend on multiple systems
Queries are open-ended
Actions matter as much as responses
You need AI systems that behave like operators
It is often combined with Hybrid, Corrective, Context-Aware, and Memory-Augmented RAG.
One-Line Summary
Agentic RAG turns retrieval into an autonomous, goal-driven process—enabling LLM systems to plan, reason, retrieve, and act like intelligent operators.
10. RL-RAG (Reinforcement Learning RAG)
RL-RAG (Reinforcement Learning–based Retrieval-Augmented Generation) is a RAG architecture where retrieval and generation decisions are optimized using reinforcement learning rather than fixed heuristics.
Instead of treating retrieval as a static step, RL-RAG learns policies for:
When to retrieve
What to retrieve
How much to retrieve
Which retriever or source to use
How to trade off cost, latency, and answer quality
The system improves over time by learning from outcomes and feedback.
What Problem Does RL-RAG Solve?
Most RAG systems rely on hand-tuned rules:
Fixed number of documents
Static retrieval strategies
One-size-fits-all pipelines
These approaches break down when:
Query complexity varies widely
Retrieval is expensive
Latency or cost constraints matter
User satisfaction is the true objective
RL-RAG solves this by optimizing retrieval behavior directly against downstream goals, not proxy metrics.
How RL-RAG Works (Step-by-Step)
State RepresentationThe system defines a state, which may include:
Query features
Conversation context
Model uncertainty
Past retrieval outcomes
System constraints (latency, cost)
Action SpacePossible actions include:
Retrieve or skip retrieval
Choose retriever type (dense, sparse, hybrid)
Adjust number of documents
Trigger follow-up retrieval
Regenerate or stop
Policy ExecutionA learned policy selects actions based on the current state.
Generation & OutcomeThe LLM generates an answer using the chosen retrieval strategy.
Reward SignalThe system receives rewards based on:
Answer quality
User feedback
Task success
Cost efficiency
Latency constraints
Policy UpdateThe policy is updated to improve future decisions.

An illustration on RL-RAG
Key Characteristics
Learning-based retrieval control
Adaptive over time
Optimizes real objectives
Balances quality, cost, and latency
Reduces unnecessary retrieval
Example
User:“Explain cancellation rules.”
Traditional RAG
Always retrieves 5 documents
Same cost and latency for every query
RL-RAG
Learns that:
Simple policy questions need minimal retrieval
Booking-specific queries need deeper retrieval
Dynamically adjusts retrieval depth
Improves efficiency without sacrificing accuracy
Where RL-RAG Is Used
High-scale consumer AI systems
Cost-sensitive enterprise platforms
Continuous-learning assistants
Personalized AI copilots
Autonomous agents with feedback loops
When You Should Use RL-RAG
RL-RAG is ideal when:
You have feedback signals (implicit or explicit)
Cost and latency matter at scale
Query difficulty varies significantly
You want systems that improve automatically
You are building long-lived AI products
RL-RAG is often layered on top of Agentic RAG, turning agents into learning agents.
One-Line Summary
RL-RAG uses reinforcement learning to optimize retrieval decisions directly against real-world objectives like quality, cost, and user satisfaction.
11. Self-RAG
Self-RAG (Self-Reflective Retrieval-Augmented Generation) is a RAG architecture where the language model introspects its own confidence and knowledge gaps and decides whether retrieval is necessary, sufficient, or should be repeated.
Instead of blindly retrieving for every query—or always trusting retrieved content—Self-RAG enables the model to self-assess, making retrieval conditional and adaptive.
In essence, the model asks itself:
“Do I know enough to answer this reliably, or should I retrieve more information?”
What Problem Does Self-RAG Solve?
Traditional RAG systems suffer from two opposite inefficiencies:
Over-retrieval
Wastes tokens, cost, and latency for simple questions
Under-retrieval
Leads to hallucinations when the model answers from weak internal knowledge
Self-RAG solves this by introducing model-driven retrieval gating, ensuring retrieval happens only when needed.
How Self-RAG Works (Step-by-Step)
Initial Self-AssessmentThe model evaluates the query and estimates:
Confidence in its internal knowledge
Risk of hallucination
Need for external grounding
Retrieve-or-Not DecisionBased on this assessment, the model decides:
Answer directly (no retrieval)
Perform retrieval
Perform deeper or iterative retrieval
Conditional RetrievalIf retrieval is triggered, documents are fetched as usual.
Post-Retrieval ReflectionThe model evaluates whether the retrieved evidence is:
Sufficient
Relevant
Consistent
Answer Generation or Re-Retrieval
If sufficient → generate answer
If insufficient → refine query and retrieve again

An illustration on Self-RAG
Key Characteristics
Self-reflection before retrieval
Dynamic retrieval depth
Reduced unnecessary context
Lower hallucination rates
Cost- and latency-efficient
Example
User:“What is a refund?”
Without Self-RAG
Always retrieves policy documents
Adds latency and cost unnecessarily
With Self-RAG
Recognizes this as a generic definition
Answers directly without retrieval
User:“What is the refund policy for my booking?”
Detects booking-specific risk
Triggers retrieval
Produces a grounded answer
Where Self-RAG Is Used
High-scale consumer chatbots
Cost-sensitive AI applications
Knowledge assistants with mixed query difficulty
Edge or mobile AI systems
Early-stage RAG pipelines
When You Should Use Self-RAG
Self-RAG is ideal when:
Many queries are simple or generic
Retrieval cost is non-trivial
Latency matters
You want smart defaults without full agent complexity
You are not ready for full RL-RAG or Agentic RAG
Self-RAG often acts as a stepping stone toward more advanced architectures.
One-Line Summary
Self-RAG empowers LLMs to reflect on their own uncertainty, triggering retrieval only when needed to balance accuracy, cost, and speed.
12. Sparse RAG
Sparse RAG (Retrieval-Augmented Generation) is a RAG architecture that relies on sparse retrieval methods—such as BM25, TF-IDF, or inverted indexes—to fetch relevant documents based on exact token overlap and term frequency, rather than semantic embeddings.
In Sparse RAG, relevance is driven by lexical signals (keywords, phrases, identifiers), making retrieval interpretable, precise, and efficient for certain classes of queries.
What Problem Does Sparse RAG Solve?
Dense (embedding-based) retrieval excels at semantic similarity but struggles with:
Exact matches (IDs, codes, SKUs, booking numbers)
Rare or domain-specific terms
Numeric-heavy queries
Strict compliance and auditability requirements
Sparse RAG solves this by using deterministic, keyword-driven retrieval, ensuring that what you search for is exactly what you retrieve.
How Sparse RAG Works (Step-by-Step)
Query TokenizationThe user query is tokenized into keywords and terms.
Sparse Index LookupThe system searches an inverted index using methods like:
BM25
TF-IDF
Exact-Match ScoringDocuments are scored based on:
Term frequency
Inverse document frequency
Token overlap
Top-K SelectionThe highest-scoring documents are selected.
Grounded GenerationThe LLM generates a response strictly grounded in the retrieved documents.

An illustration on Sparse RAG
Key Characteristics
Exact keyword matching
High interpretability
Fast and cost-efficient
Strong on IDs, codes, and rare terms
Deterministic behavior
Example
User:“What is the refund status for booking ID 12T5PR74?”
Dense RAG
May miss the exact booking ID
Retrieves generic refund policies
Sparse RAG
Matches booking ID exactly
Retrieves booking-specific record
Produces a precise answer
Where Sparse RAG Is Used
Legal and compliance systems
Financial and auditing tools
Enterprise logs and ticketing systems
Booking, billing, and inventory platforms
Domains requiring explainability
When You Should Use Sparse RAG
Sparse RAG is ideal when:
Queries involve IDs, codes, or exact phrases
Precision is more important than semantic recall
Explainability and auditability are required
Data is highly structured or technical
You want low-latency, low-cost retrieval
In practice, Sparse RAG is often combined with Dense RAG in Hybrid or Fusion
RAG systems.
One-Line Summary
Sparse RAG uses keyword-based retrieval to deliver precise, interpretable, and highly reliable grounding—especially for exact-match and compliance-critical use cases.
13. Adaptive RAG
Adaptive RAG (Retrieval-Augmented Generation) is a RAG architecture that dynamically adjusts its retrieval strategy at runtime based on the query’s complexity, ambiguity, confidence signals, cost constraints, and system context.
Instead of using a fixed retrieval setup (same retriever, same top-K, same depth for every query), Adaptive RAG adapts how much, how deep, and how often it retrieves—on a per-query basis.
In short, it answers:
“How much retrieval does this query actually need?”
What Problem Does Adaptive RAG Solve?
Traditional RAG pipelines are static:
Same number of documents for every query
Same retriever regardless of query type
Same latency and cost profile
This leads to:
Over-retrieval for simple questions (wasted cost/latency)
Under-retrieval for complex questions (hallucinations)
Poor performance across mixed workloads
Adaptive RAG solves this by right-sizing retrieval to the problem, not the pipeline.
How Adaptive RAG Works (Step-by-Step)
Query & Context AnalysisThe system analyzes signals such as:
Query length and specificity
Ambiguity and uncertainty
Presence of IDs, dates, entities
User intent and context
Latency or cost budgets
Retrieval Strategy SelectionBased on the analysis, the system chooses:
No retrieval (answer directly)
Shallow retrieval (few docs)
Deep retrieval (many docs)
Retriever type (dense, sparse, hybrid)
Single-shot vs multi-hop retrieval
Dynamic Retrieval ExecutionRetrieval is executed with the selected configuration.
Confidence Check (Optional)If confidence is still low, the system can:
Increase retrieval depth
Switch retrievers
Trigger corrective steps
Grounded Generation: The LLM generates a response using the adaptively retrieved context.

An illustration on Adaptive RAG
Key Characteristics
Query-dependent retrieval
Dynamic top-K and retriever choice
Balances accuracy, latency, and cost
Scales well across diverse workloads
Minimal architectural overhead
Example
Query 1:“What is a refund?”
Low ambiguity
General knowledge
→ No retrieval
Query 2:“What is the refund policy for booking ID 12T5PR74?”
Booking-specific
High risk if wrong
→ Deep retrieval + exact-match lookup
Adaptive RAG handles both efficiently without separate systems.
Where Adaptive RAG Is Used
Enterprise assistants with mixed queries
Cost-sensitive AI platforms
High-traffic customer support systems
AI copilots for internal tools
Early-stage agentic systems
When You Should Use Adaptive RAG
Adaptive RAG is ideal when:
Query difficulty varies widely
Cost and latency matter
You want smarter defaults without full RL
You operate at scale
You want one system for many use cases
In practice, Adaptive RAG is one of the highest ROI RAG upgrades.
One-Line Summary
Adaptive RAG dynamically tunes retrieval strategy per query, delivering the right balance of accuracy, speed, and cost across diverse workloads.
14. Citation-Aware RAG
Citation-Aware RAG (Retrieval-Augmented Generation) is a RAG architecture designed to explicitly track, preserve, and surface citations for every factual claim made by the language model.
Instead of merely grounding answers in retrieved documents, Citation-Aware RAG ensures that:
Each statement can be traced back to a source
Citations are linked, scoped, and verifiable
The model knows what it knows and where it came from
This turns RAG from a helpful assistant into a trustworthy, auditable system.
What Problem Does Citation-Aware RAG Solve?
Standard RAG systems retrieve documents but often fail to:
Clearly attribute facts to sources
Distinguish between retrieved knowledge and model inference
Support audits, compliance checks, or verification
This leads to:
Low trust in high-stakes domains
Difficulty validating answers
Regulatory and legal risks
Citation-Aware RAG solves this by making attribution a first-class output, not an afterthought.
How Citation-Aware RAG Works (Step-by-Step)
Document Retrieval with MetadataRetrieved documents include:
Source identifiers
Document IDs
Section, paragraph, or sentence boundaries
Citation-Preserving Context ConstructionRetrieved content is chunked and passed to the model with explicit citation markers.
Evidence-Aware GenerationThe model generates responses while:
Linking claims to specific sources
Avoiding unsupported statements
Flagging uncertainty when evidence is missing
Citation Alignment & ValidationEach sentence or claim is aligned with one or more citations.
Structured OutputThe final response includes:
Inline citations
Footnotes
Source lists
Confidence indicators (optional)

An illustration on Citation-Aware RAG
Key Characteristics
Explicit source attribution
Claim-level grounding
Audit-friendly outputs
Reduced hallucination risk
High user trust
Example
User:“What is the cancellation policy for this booking?”
Without Citation-Aware RAG
Provides correct-looking answer
Source unclear
Hard to verify
With Citation-Aware RAG
“You can cancel for free up to 24 hours before check-in. Booking Policy, Section 3.2”
Each claim is traceable to a specific document and section.
Where Citation-Aware RAG Is Used
Legal research tools
Healthcare decision support
Financial and regulatory reporting
Enterprise policy assistants
Academic and scientific research
When You Should Use Citation-Aware RAG
Citation-Aware RAG is essential when:
Decisions are high-stakes
Outputs must be auditable
Users need to verify claims
Regulations or compliance apply
Trust matters more than fluency
It is often mandatory in enterprise and regulated environments.
One-Line Summary
Citation-Aware RAG transforms RAG outputs into verifiable, auditable answers by explicitly linking every claim to its source.
15. REFEED RAG
REFEED RAG (Retrieve–Evaluate–Feed-back Retrieval-Augmented Generation) is a RAG architecture where the model’s own generated output is fed back into the retrieval and reasoning loop to iteratively improve answer quality.
Instead of treating generation as the final step, REFEED RAG treats it as a checkpoint. The system continuously asks:
“Is this answer complete, correct, and well-supported—or should I retrieve more information and refine it?”
This makes REFEED RAG an iterative refinement system rather than a one-shot pipeline.
What Problem Does REFEED RAG Solve?
Standard RAG systems often fail when:
Initial retrieval misses important details
Answers are partially correct but incomplete
Complex questions require synthesis across multiple angles
The model needs to rethink and refine its response
REFEED RAG solves this by introducing self-improving loops, allowing answers to converge toward higher quality through repeated retrieval and evaluation.
How REFEED RAG Works (Step-by-Step)
Initial RetrievalThe system retrieves documents based on the user query.
First-Pass GenerationThe LLM generates an initial answer using the retrieved context.
Answer EvaluationThe system evaluates the generated answer for:
Missing information
Weak evidence
Unanswered sub-questions
Logical gaps
Feedback-to-Retrieval (Refeed)Insights from the evaluation are converted into new retrieval queries.
Example: “Retrieve exceptions to the cancellation policy”
Refined RetrievalAdditional or more targeted documents are retrieved.
Answer RefinementThe LLM regenerates or edits the answer using the expanded evidence.
Loop Until Satisfied (Optional)The cycle continues until confidence or quality thresholds are met.

An illustration on REFEED RAG
Key Characteristics
Iterative refinement
Answer-driven retrieval
Progressive completeness
Reduced partial answers
High reasoning depth
Example
User:“Explain the full refund policy for this booking.”
Standard RAG
Retrieves main policy
Misses exceptions and edge cases
REFEED RAG
Generates initial answer
Detects missing penalty clauses
Retrieves exception rules
Refines answer to include all conditions
Where REFEED RAG Is Used
Research and analysis assistants
Legal and policy interpretation tools
Technical documentation synthesis
Financial and compliance reporting
Long-form answer generation
When You Should Use REFEED RAG
REFEED RAG is ideal when:
Questions are complex or multi-dimensional
Partial answers are unacceptable
Depth matters more than latency
You want self-improving responses
You are building research-grade or expert systems
It is often combined with Corrective RAG and Citation-Aware RAG.
One-Line Summary
REFEED RAG iteratively feeds generated answers back into retrieval, enabling progressively refined, complete, and high-quality responses.
16. Multimodal RAG
Multimodal RAG (Retrieval-Augmented Generation) is a RAG architecture that retrieves, reasons over, and generates responses using multiple data modalities—such as text, images, tables, charts, audio, video, and PDFs—rather than text alone.
Instead of asking “Which documents are relevant?”, Multimodal RAG asks:
“Which combination of modalities best answers this question?”
This enables LLM systems to understand and respond to real-world, information-rich inputs.
What Problem Does Multimodal RAG Solve?
Text-only RAG breaks down when:
Information is embedded in images, diagrams, or tables
Answers require visual grounding
Documents are PDFs, scans, or reports
Users ask questions like “What does this chart show?” or “Is this image compliant?”
Multimodal RAG solves this by making non-text data first-class retrieval and reasoning inputs.
How Multimodal RAG Works (Step-by-Step)
Multimodal Ingestion & IndexingContent is ingested and indexed by modality:
Text → embeddings / sparse indexes
Images → vision embeddings
Tables → structured or hybrid embeddings
Audio / Video → transcripts + temporal metadata
Multimodal Query UnderstandingThe user query may include:
Text
Images
Screenshots
Files (PDFs, reports)
Cross-Modal RetrievalThe system retrieves:
Relevant text passages
Related images or diagrams
Supporting tables or chartsRetrieval may happen per modality or jointly.
Modality FusionRetrieved evidence from different modalities is aligned and ranked:
Image ↔ text alignment
Table ↔ explanation alignment
Multimodal GenerationThe LLM generates a response grounded in all retrieved modalities, often referencing or explaining visual elements.

An illustration on multimodal RAG. Image Credits
Key Characteristics
Cross-modal retrieval
Visual + textual grounding
Richer context understanding
Handles real-world documents
Reduces misinterpretation of visual data
Example
User:“Does this hotel image meet brand standards?”
Without Multimodal RAG
Uses text-only policies
Cannot assess the image
With Multimodal RAG
Retrieves:
Brand guideline document (text)
Uploaded hotel image (vision)
Compares visual features with standards
Produces a grounded, explainable assessment
Where Multimodal RAG Is Used
Document intelligence and PDF analysis
Visual compliance and quality checks
Medical imaging + reports
E-commerce product understanding
Enterprise knowledge assistants
When You Should Use Multimodal RAG
Multimodal RAG is essential when:
Knowledge is not purely textual
Visual evidence matters
Users upload files, images, or screenshots
Decisions depend on diagrams, charts, or photos
You want human-like understanding of content
One-Line Summary
Multimodal RAG enables LLMs to retrieve and reason across text, images, tables, and more—bringing RAG closer to real-world understanding.
17. Multi-Hop RAG
Multi-Hop RAG (Retrieval-Augmented Generation) is a RAG architecture designed to answer complex questions that require multiple, sequential retrieval steps, where each retrieval depends on the results of the previous one.
Instead of retrieving all information in a single step, Multi-Hop RAG chains retrievals together, allowing the system to progressively build understanding across multiple pieces of knowledge.
In essence, it answers questions that require:
“Find A → use A to find B → use B to answer the question.”
How Multi-Hop RAG Works (Step-by-Step)
Initial Query DecompositionThe system breaks the user question into sub-questions or reasoning steps.
First-Hop RetrievalThe system retrieves documents relevant to the first sub-question.
Intermediate ReasoningThe model extracts key entities, facts, or constraints from the first-hop results.
Second (or Nth) Hop RetrievalUsing extracted information, the system performs a new retrieval targeting the next missing piece.
Evidence AccumulationRetrieved evidence from multiple hops is accumulated and aligned.
Final Grounded GenerationThe LLM generates the final answer using evidence gathered across all hops.

An illustration on Multi-hop RAG. Image Credits
Key Characteristics
Sequential retrieval
Intermediate reasoning
Evidence accumulation
Handles indirect questions
High reasoning depth
Example
User:“Which company acquired the startup founded by the creator of Kubernetes?”
Single-Hop RAG
Retrieves Kubernetes overview
Fails to connect founder → startup → acquisition
Multi-Hop RAG
Retrieves Kubernetes → identifies founder (Joe Beda)
Retrieves startup founded by Joe Beda (Heptio)
Retrieves acquisition details of Heptio (VMware)
Produces correct, grounded answer
Where Multi-Hop RAG Is Used
Research and analytical assistants
Question answering over encyclopedic knowledge
Legal and compliance reasoning
Technical troubleshooting
Intelligence and investigation systems
When You Should Use Multi-Hop RAG
Multi-Hop RAG is essential when:
Questions require chaining facts
Information is spread across sources
The query cannot be answered with a single lookup
Reasoning depth matters more than latency
It is commonly combined with Agentic RAG and REFEED RAG.
One-Line Summary
Multi-Hop RAG enables LLMs to answer complex questions by chaining multiple retrieval steps, each informed by intermediate reasoning.
18. Reasoning RAG
Reasoning RAG (Retrieval-Augmented Generation) is a RAG architecture that explicitly integrates structured reasoning mechanisms—such as chain-of-thought, symbolic reasoning, logic rules, or graphs—on top of retrieved knowledge to produce well-justified, logically coherent answers.
Instead of treating retrieval as sufficient grounding, Reasoning RAG focuses on how retrieved facts are combined, evaluated, and reasoned over before generating a response.
In short, it answers not just “What is the answer?” but “Why is this the answer?”
What Problem Does Reasoning RAG Solve?
Standard RAG systems often:
Retrieve correct information
But combine it poorly
Or produce answers without clear logical justification
This leads to:
Shallow or brittle answers
Incorrect conclusions from correct facts
Poor handling of “why”, “how”, and “what if” questions
Reasoning RAG solves this by making reasoning a first-class step, not an implicit byproduct of generation.
How Reasoning RAG Works (Step-by-Step)
Knowledge RetrievalRelevant documents, facts, or data points are retrieved using standard RAG techniques.
Fact Extraction & StructuringRetrieved content is transformed into structured representations:
Facts
Rules
Entities and relations
Constraints
Reasoning LayerThe system applies reasoning techniques such as:
Chain-of-thought reasoning
Tree-of-thought reasoning
Logical inference
Graph traversal
Consistency & Validity ChecksIntermediate reasoning steps are evaluated for:
Logical consistency
Contradictions
Missing assumptions
Grounded Answer GenerationThe final response is generated based on the reasoning trace and supporting evidence.

An illustration on Reasoning RAG
Key Characteristics
Explicit reasoning steps
Transparent logic
Handles “why” and “how” questions
Reduces reasoning hallucinations
Produces defensible answers
Example
User:“Is this booking eligible for a refund?”
Standard RAG
Retrieves refund policy
States eligibility without explanation
Reasoning RAG
Retrieves:
Booking date
Cancellation time
Refund rules
Applies logic:
If cancellation ≤ 24 hours → no refund
Booking canceled at 18 hours → not eligible
Produces a clear, justified answer
Where Reasoning RAG Is Used
Legal and compliance systems
Financial decision support
Healthcare diagnostics
Policy interpretation tools
Enterprise analytics and audits
When You Should Use Reasoning RAG
Reasoning RAG is essential when:
Answers must be explainable
Decisions are logic-driven
Users ask “why” or “how”
Incorrect reasoning is costly
You want transparent AI systems
It is commonly combined with Multi-Hop RAG, Citation-Aware RAG, and Agentic RAG.
One-Line Summary
Reasoning RAG augments retrieval with explicit logic and structured reasoning, enabling LLMs to produce explainable, defensible, and logically sound answers.
19. Long-Context RAG
Long-Context RAG (Retrieval-Augmented Generation) is a RAG architecture optimized for LLMs with large context windows, where the system can ingest, organize, and reason over very large volumes of retrieved information—often tens or hundreds of thousands of tokens—in a single prompt.
Unlike traditional RAG, which focuses on aggressively shrinking context due to token limits, Long-Context RAG asks:
“How do we best structure and prioritize information when the model can see a lot?”
The emphasis shifts from minimizing tokens to maximizing signal.
What Problem Does Long-Context RAG Solve?
Classic RAG pipelines are constrained by small context windows, forcing systems to:
Retrieve very few chunks
Over-compress information
Risk missing critical details
This becomes problematic when:
Documents are long (contracts, reports, manuals)
Context spans many sections
Answers require global understanding, not local snippets
Long-Context RAG solves this by leveraging large context windows to include broader, richer evidence, while still maintaining structure and relevance.
How Long-Context RAG Works (Step-by-Step)
Broad RetrievalThe system retrieves a larger-than-usual set of documents or sections relevant to the query.
Context StructuringInstead of blindly stuffing text, the system:
Orders documents logically
Groups related sections
Adds headings, separators, or summaries
Selective Compression (Optional)Less relevant sections may be lightly summarized, while critical sections are kept verbatim.
Large-Context InjectionThe structured context is injected into the LLM’s large context window.
Global Reasoning & GenerationThe model reasons across the entire body of evidence, enabling holistic answers.

An illustration on Long-Context RAG
Key Characteristics
Uses large context windows effectively
Preserves more original content
Supports document-level reasoning
Reduces over-aggressive chunking
Improves completeness and coherence
Example
User:“Summarize all refund-related clauses in this 120-page contract.”
Standard RAG
Retrieves a few scattered clauses
Misses cross-references and exceptions
Long-Context RAG
Retrieves all refund-related sections
Preserves section order and references
Produces a complete, structured summary
Where Long-Context RAG Is Used
Contract and legal analysis
Policy and compliance review
Technical manuals and SOPs
Financial and regulatory reports
Enterprise document intelligence
When You Should Use Long-Context RAG
Long-Context RAG is ideal when:
Documents are long and structured
Answers require global context
Missing details are costly
You have access to large-context models
You want fewer retrieval heuristics
It is often paired with Context-Ranking RAG and Reasoning RAG.
One-Line Summary
Long-Context RAG leverages large context windows to reason holistically over extensive retrieved content, enabling more complete and accurate answers for long documents.
20. Federated RAG
Federated RAG (Retrieval-Augmented Generation) is a RAG architecture where retrieval happens across multiple distributed, siloed, or independently governed data sources, without centralizing the data into a single store.
Instead of pulling all knowledge into one index, Federated RAG brings the query to the data, retrieves evidence locally from each source, and then aggregates results at generation time.
In simple terms, it answers:
“How do we reason across many knowledge silos without moving or exposing the data?”
What Problem Does Federated RAG Solve?
Centralized RAG systems break down when:
Data lives across organizations, teams, or regions
Regulations prohibit data movement (GDPR, HIPAA, internal policies)
Knowledge ownership must remain local
Systems operate at enterprise or ecosystem scale
Federated RAG solves this by enabling cross-domain reasoning while preserving data sovereignty and privacy.
How Federated RAG Works (Step-by-Step)
Query Dispatch (Federation Layer)The user query is dispatched to multiple independent retrieval endpoints:
Department-level knowledge bases
Partner systems
Regional data stores
On-prem or private clouds
Local Retrieval (Per-Silo)Each data source performs retrieval locally using its own:
Index
Permissions
Policies
Retrieval strategy
Result AbstractionEach silo returns:
Relevant snippets or summaries
Metadata and access constraints
Confidence or relevance scores
Federated AggregationResults are aggregated, normalized, and optionally re-ranked without exposing raw data.
Grounded GenerationThe LLM generates a unified answer grounded in multi-silo evidence, respecting access and policy boundaries.

An illustration on Federated RAG
Key Characteristics
No data centralization
Privacy- and compliance-first
Cross-silo reasoning
Source-aware aggregation
Scales across organizations
Example
User:“What are the cancellation rules across all EU markets?”
Centralized RAG
Requires copying regional policies into one store
Violates governance or ownership constraints
Federated RAG
Queries each regional policy system independently
Aggregates country-level rules
Produces a compliant, consolidated answer
Where Federated RAG Is Used
Large enterprises with departmental silos
Multi-country or multi-region organizations
Regulated industries (finance, healthcare, government)
Partner ecosystems and marketplaces
Hybrid cloud and on-prem deployments
When You Should Use Federated RAG
Federated RAG is ideal when:
Data cannot be centralized
Ownership and sovereignty matter
Policies differ by region or unit
You need enterprise-scale reasoning
Trust boundaries must be respected
It is often a non-negotiable requirement in regulated environments.
One-Line Summary
Federated RAG enables LLMs to reason across distributed knowledge sources while preserving data privacy, ownership, and regulatory boundaries.
21. Hierarchical RAG
Hierarchical RAG is a Retrieval-Augmented Generation architecture designed to handle large, complex knowledge bases by organizing information into multiple levels of abstraction. Instead of retrieving chunks from a flat document store, it mirrors how humans reason—starting broad, then drilling down into details.
Instead of asking “Which chunks are relevant?”, Hierarchical RAG asks:
“Which document is relevant first, then which section inside it, and finally which passage best answers the question?”
How Hierarchical RAG Works
Hierarchical Knowledge StructureContent is indexed at multiple levels, for example:
Level 1: High-level summaries (domains, topics, sections)
Level 2: Mid-level concepts (chapters, subtopics)
Level 3: Fine-grained chunks (paragraphs, facts, tables)
Top-Down Retrieval
The system first retrieves coarse summaries relevant to the query.
Based on these, it selectively dives into more specific sub-sections.
Only the most relevant fine-grained content reaches the LLM.
Context-Efficient GenerationBy narrowing the search space step by step, the model avoids flooding the context window with irrelevant chunks.
Why Hierarchical RAG Matters
Scales to massive corpora (books, policies, codebases, enterprise wikis)
Reduces noise compared to flat vector search
Improves reasoning quality by preserving structure and intent
Optimizes token usage, crucial for long-context and cost control

An illustration on Hierarchical RAG
Key Characteristics
Multi-resolution embeddings (doc, section, paragraph)
Cascaded retrieval instead of flat similarity search
Context preservation across levels
Lower hallucination risk due to structured grounding
When You Should Use Hierarchical RAG
Use Hierarchical RAG if:
Your documents are long and structured
Answers require both global understanding and local precision
You want better faithfulness with fewer retrieved tokens
You are scaling RAG to enterprise or research-grade systems
Avoid it if:
Your corpus is small or unstructured
Latency must be ultra-low and retrieval is trivial
One-Line Summary
Flat RAG retrieves chunks. Hierarchical RAG retrieves meaning—step by step.
22. Context-Ranking RAG
Context-Ranking RAG is a Retrieval-Augmented Generation architecture that explicitly ranks, filters, and prioritizes retrieved context before generation—ensuring that only the most relevant, trustworthy, and useful information enters the LLM’s context window.
Instead of assuming that all retrieved chunks are equally useful, Context-Ranking RAG asks:
“Which retrieved context deserves to be seen by the model first—or at all?”
Why Context-Ranking RAG Exists
Standard RAG systems often fail after retrieval:
Retrieved chunks may be loosely relevant
Important evidence may be buried deep in the context
LLM context windows get polluted with noise
Token budgets are wasted on low-value passages
Context-Ranking RAG addresses this by inserting an intelligent ranking layer between retrieval and generation.
How Context-Ranking RAG Works
Initial Retrieval (Recall-Focused)
Vector, hybrid, or keyword search retrieves a large candidate set
Goal: maximize recall, not precision
Context Scoring & Ranking
Each chunk is scored using one or more signals:
Semantic relevance
Query-passage alignment
Freshness
Authority or source reliability
Metadata signals (section, document type)
Reranking (Critical Step)
A cross-encoder, LLM-based judge, or learning-to-rank model reorders contexts
Top-N chunks are selected
Context Compression (Optional)
Low-ranked chunks are dropped or summarized
High-ranked chunks are preserved verbatim
LLM Generation
The LLM receives rank-ordered, high-signal context
Produces more grounded and concise answers
Common Ranking Techniques Used
Cross-encoders (query + passage jointly evaluated)
LLM-as-a-Judge scoring relevance
Reciprocal Rank Fusion (RRF)
Learning-to-Rank (LambdaMART, XGBoost)
Heuristic + metadata scoring
Attention-based relevance scoring

An illustration of Context-Ranking RAG
When Context-Ranking RAG Is Essential
Use Context-Ranking RAG when:
Your retrieval returns many similar chunks
Documents overlap heavily (policies, FAQs, logs)
LLM context windows are limited
You care about precision over verbosity
You want consistent answer quality at scale
It is especially effective in:
Enterprise knowledge assistants
Legal and compliance systems
Customer support bots
Research copilots
Observability and log analysis tools
One-Line Summary
Context-Ranking RAG recognizes that what you show the model matters more than what you retrieve.
23. Prompt-Augmented RAG
Prompt-Augmented RAG is a Retrieval-Augmented Generation architecture where the prompt itself actively guides retrieval, context selection, and generation, rather than acting only as a final instruction to the LLM.
Instead of treating the prompt as a passive input, Prompt-Augmented RAG treats it as a first-class control layer that shapes what is retrieved, how it is interpreted, and how the answer is constructed.
Why Prompt-Augmented RAG Exists
In classic RAG pipelines, prompts are often an afterthought:
Retrieval happens independently of user intent nuances
The same retrieval logic is used for very different questions
The LLM receives context but lacks guidance on how to use it
This leads to:
Over-retrieval or under-retrieval
Correct context used incorrectly
Answers that ignore constraints, tone, or reasoning style
Prompt-Augmented RAG fixes this by injecting intent, constraints, and reasoning instructions earlier in the pipeline.
Core Idea
Instead of asking:
“What documents match this query?”
Prompt-Augmented RAG asks:
“Given this task, intent, and reasoning style, what information should be retrieved—and how should it be used?”
How Prompt-Augmented RAG Works
Structured Prompt Understanding
The prompt is decomposed into:
User intent (inform, compare, explain, decide)
Constraints (time, geography, format, accuracy)
Reasoning style (step-by-step, summary, critical analysis)
Output expectations
Prompt-Conditioned Retrieval
Retrieval queries are rewritten or expanded using prompt signals
Different prompts may trigger:
Different search strategies
Different corpora
Different retrieval depth
Prompt-Aware Context Selection
Retrieved chunks are filtered or ranked based on prompt intent
Example:
“Summarize” → broader context
“Verify” → authoritative sources only
“Compare” → multiple viewpoints
Prompt-Guided Generation
The final prompt explicitly instructs:
How to use retrieved context
What to ignore
How to structure the answer

An illustration on Prompt-Augmented RAG
Key Characteristics
Query rewriting prompts
Intent classification prompts
Task-specific retrieval prompts
Chain-of-thought or reasoning prompts
Role-based prompts (analyst, auditor, tutor)
Source-control prompts (only policies, only research, etc.)
Where Prompt-Augmented RAG Excels
Enterprise Q&A with mixed intent queries
Research assistants (explore vs validate vs summarize)
Decision-support systems
Legal and compliance analysis
Multi-persona assistants
Complex instructions with strict output formats
One-Line Summary
Standard RAG asks the model to answer using retrieved text. Prompt-Augmented RAG tells the system how to think, what to retrieve, and how to answer.
Conclusion
RAG is no longer a single pattern—it is a design space. Modern systems increasingly combine multiple RAG types (e.g., Agentic + Citation-Aware + Adaptive) to balance accuracy, latency, trust, and reasoning depth. Choosing the right RAG variant depends less on model size and more on task complexity, data distribution, and user



For anyone looking to broaden their skill set, the Global Skills Meet offers a platform filled with interactive workshops and engaging discussions. Attendees can explore a range of topics that reflect today’s most relevant skills. The event fosters a supportive community where learning is shared and celebrated. With opportunities to engage directly with facilitators, every session adds value.