
The Dragon Hatchling (BDH): Bridging Transformers and Brain-Like Reasoning
- Nagesh Singh Chauhan
- Dec 21, 2025
- 10 min read

Modern neural networks can recognize faces, write stories, and even pass programming interviews — but they all share the same limitation: they stop learning once deployed.

Introduction
Over the last decade, the Transformer architecture has become the backbone of modern artificial intelligence. From large language models to multimodal systems, Transformers have demonstrated an extraordinary ability to learn patterns from massive datasets and generate fluent, coherent outputs. Yet despite their success, they reveal a fundamental limitation: once training ends, learning stops. During inference, these models execute what they have learned but do not adapt, reflect, or evolve based on new experience.
This limitation becomes especially visible in long-horizon reasoning, agentic systems, and interactive settings. As tasks grow more complex and contexts extend over time, Transformers struggle to maintain coherence, stability, and interpretability. Their attention is recalculated at every step, memory is implicit and transient, and internal representations remain difficult to inspect or control. These characteristics make them powerful pattern predictors—but weak learners once deployed.
The Dragon Hatchling (BDH) architecture proposes a different way forward. Instead of treating intelligence as a static function computed by frozen weights, BDH models intelligence as a dynamic system—one that learns before deployment and continues learning while operating. Inspired by biological brains, BDH introduces explicit short-term memory, synaptic plasticity, and local learning rules that allow the model to adapt in real time without retraining.
This blog explores how BDH differs fundamentally from Transformers. Rather than focusing on raw performance numbers, we compare the two architectures across learning behavior, memory, attention, interpretability, scalability, and long-term reasoning. The goal is not to declare a winner, but to understand what kind of intelligence each architecture is built to support—and why BDH represents a meaningful shift in how future AI systems may be designed.
How Today’s AI Models Learn
Most modern AI models follow a strict two-phase lifecycle:
Phase 1: Training
Large datasets
Gradient descent
Heavy GPU usage
Model weights are adjusted
Phase 2: Inference (Usage)
The model generates outputs
No internal learning happens
All weights are frozen

In simple terms:
Today’s AI learns inside the egg—and then stops.
This works well for pattern recognition, but it limits:
Adaptation to new situations
Long reasoning chains
Context-aware learning
What Is Dragon Hatchling (BDH)?
At its core, Dragon Hatchling (BDH) is a new large language model architecture that treats computation as a network of locally interacting “neuron particles” connected by adaptive synapses, rather than as layers of dense matrices.
Uses neurons like components: What makes BDH unique is its close alignment with how real brains work. The architecture is built from neuron-like components, including excitatory and inhibitory circuits, and uses integrate-and-fire dynamics where neurons accumulate signals until they cross a threshold and activate. Most importantly, BDH applies Hebbian learning—the neuroscience principle often summarized as “neurons that fire together, wire together.”
Memory lives in the connections: In BDH, memory is not stored in abstract activation vectors but lives directly in the connections between neurons. These synaptic links strengthen or weaken based on what the model is processing at that moment. As BDH reasons about a concept, specific connections update in real time, making it possible to observe how the model forms and uses short-term memory.
Interpretable by design: It relies on sparse, positive-only activations that are easier to analyze, and experiments show the emergence of monosemantic synapses—individual connections that consistently represent specific concepts across different contexts. This leads to an internal state that can be inspected and understood, rather than inferred after the fact.
A Scale-Free Network
BDH’s structure mimics the scale-free networks found in biological brains — where some neurons are highly connected hubs and many others have fewer connections. This topology:
Supports modular processing
Encourages efficient communication patterns
Enables robust emergence of function
This contrasts sharply with the dense uniform connectivity of traditional Transformers.
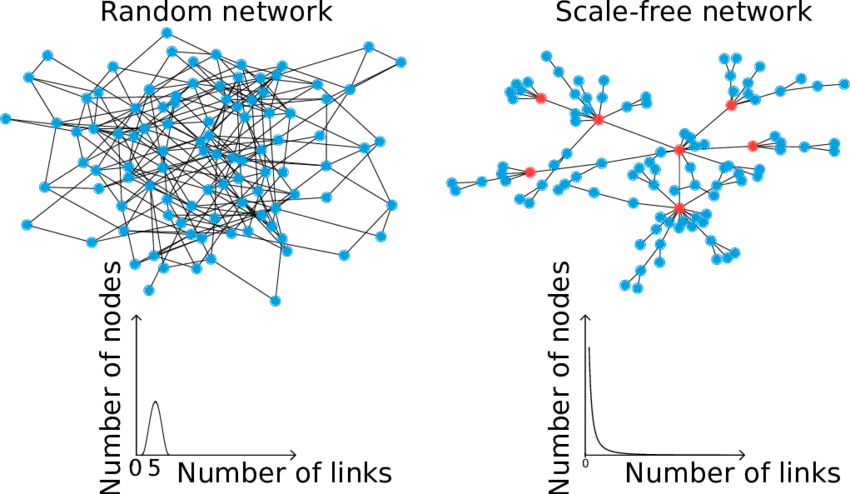
A scale free network is a network in which the degree distribution follows the power law. Image Credits
Hebbian Plasticity in Action
While Transformers rely on fixed weights learned during training, BDH employs Hebbian learning (“neurons that fire together wire together”) during inference. This means synaptic weights adapt in response to input signals in real time, forming short-term memories that influence future reasoning — akin to real neural dynamics.

Hebbian Learning is a bio-inspired learning paradigm that takes inspiration from the observed principles of synaptic plasticity in the human brain. The term “Hebbian” comes from the psychologist Donald Hebb, who introduced the concept in 1949 with the famous phrase, “Neurons that fire together, wire together”. Image Credits
GPU-Friendly State Space Formulation
BDH also includes a tensor-friendly variant (BDH-GPU) that can be trained with standard GPU hardware. This makes the model compatible with existing deep learning software while retaining its biologically inspired mechanisms. GitHub
Why the “Dragon Hatchling” Metaphor?
Imagine a young dragon just after it hatches. It already has basic abilities—it can stand, flap its wings, maybe even produce a spark of fire. But it doesn’t learn from textbooks. It learns by acting, by making mistakes, and by remembering what worked while flying.
That is the core idea behind the Dragon Hatchling AI:
Learning happens during experience, not only before it

What Makes the Dragon Hatchling Different?
The Dragon Hatchling introduces two kinds of memory instead of one.
1. Permanent Memory (Long-Term Knowledge)
This is similar to traditional neural networks:
Learned during training
Stores language, facts, patterns
Remains fixed during usage
Think of this as the dragon’s instincts at birth.
2. Temporary Memory (Learning While Thinking)
This is the breakthrough.
While the model is running, it creates temporary connections between neurons. If two neurons activate together, their connection strengthens. If they stop being useful, the connection fades.
This follows a simple biological rule called Hebbian learning:
“Neurons that fire together, wire together.”

Here we see how neuron i (bottom) receives information from the few neurons j (top) that still have active connections in the sparse Gₛ. These connections are the result of selection ('sparsification') from the initially dense attention σ. Image Credits
The σ (Sigma) Memory: Working Memory in Action
The Dragon Hatchling stores temporary learning in a structure called σ (sigma).
You can think of σ as:
Short-term memory
A map of recent thoughts
A record of “what mattered just now”
Mathematically, a simplified update looks like this:

Where:
σij is the connection between neuron i and j
u controls forgetting
η controls learning speed
x and y are neuron activations
Key properties:
σ updates during inference
No backpropagation
No retraining
Resets after the session ends
This prevents permanent damage to long-term knowledge.
Transformer vs BDH (Dragon Hatchling)
Two Very Different Ways of Building Intelligence
Transformers and the Dragon Hatchling (BDH) represent two fundamentally different philosophies of how intelligence should be built in machines. While both can achieve similar performance on language tasks, the way they learn, remember, and reason over time is very different.
Core Design Philosophy
Transformers view intelligence as a centralized computation problem. They process sequences using stacked layers of dense matrix operations, where attention is recalculated at every step. Once trained, their internal structure is fixed.
BDH, in contrast, treats intelligence as a distributed system of neurons and synapses. Reasoning emerges from local interactions between neurons, and memory lives on the connections between them. Learning is not limited to training time—it continues during inference.
In short:
Transformers compute intelligence.
BDH behaves like an intelligent system.
Learning Behavior
Transformers learn only during training. After deployment, their weights are frozen, and any adaptation requires explicit retraining, fine-tuning, or parameter-efficient updates such as LoRA.
BDH introduces two learning speeds:
Slow learning during training, using gradient descent.
Fast learning during inference, using Hebbian-style updates.
Key differences:
Transformers do not learn from experience once deployed.
BDH adapts while reasoning, without backpropagation or retraining.
BDH’s inference-time learning is temporary and safely reset.
Memory and State
Transformers rely on implicit memory through hidden states and KV caches. This memory:
Is recomputed every step
Grows with context length
Is not explicitly interpretable
BDH uses an explicit synaptic memory (σ):
Stored on neuron-to-neuron connections
Updated during inference
Decays naturally over time
This leads to:
Controlled forgetting instead of abrupt truncation
Stable long-context behavior
Clear separation between short-term and long-term memory
Attention Mechanism
In Transformers, attention is a dense mathematical operation involving queries, keys, and values. It is powerful but opaque and stateless.
BDH treats attention as persistent memory:
Signals flow through synapses strengthened by recent context
Only relevant connections remain active
Attention is sparse, localized, and interpretable
Key contrast:
Transformer attention is recalculated.
BDH attention is remembered.
Interpretability
Transformers are notoriously difficult to interpret. Neurons and attention heads often represent multiple unrelated concepts, making debugging and auditing challenging.
BDH was designed with interpretability in mind:
Activations are sparse and positive
Individual connections correspond to specific relationships
Reasoning paths can be inspected directly
This makes BDH attractive for:
Regulated industries
Safety-critical applications
Explainable AI use cases
Reasoning Over Long Horizons
Transformers struggle when reasoning exceeds their trained context length. As sequences grow longer:
Coherence degrades
KV caches grow large
Errors compound
BDH is designed as a scale-free system:
Behavior remains stable as reasoning depth increases
Memory fades smoothly instead of exploding
Suitable for long-running agents and planners
Model Composition and Modularity
Combining Transformers is difficult and often destructive. Merging two models usually requires retraining and risks catastrophic forgetting.
BDH supports native model merging:
Two models can be combined by connecting their graphs
No retraining required
Knowledge from both models is preserved
This enables modular AI systems where intelligence can be assembled like components.
Computational Characteristics
Transformers rely on deep stacks of layers and large KV caches, making long-context inference expensive.
BDH-GPU reformulates BDH as a state-space system:
Linear scaling with model size
GPU-friendly training and inference
Naturally compatible with neuromorphic hardware
This makes BDH accessible even at modest parameter scales (10M–1B).
Transformers represent the peak of static intelligence—extremely powerful, but fixed after training. BDH represents a shift toward living intelligence—systems that adapt, remember, and regulate themselves while operating.
Transformers are brilliant at predicting the next token.BDH is designed to understand what just happened—and act accordingly.
How BDH Will Impact Large Language Models (LLMs)
BDH (Brain-like Dragon Hatchling) is not just a new neural architecture—it represents a fundamental shift in how large language models learn, remember, and reason. When integrated into LLMs, BDH transforms them from static text predictors into systems that can adapt and evolve during use.

Traditional LLMs stop learning once training ends. After deployment, they execute frozen knowledge, unable to adjust their internal state based on experience. BDH breaks this limitation by introducing inference-time learning, allowing models to adapt while reasoning—much like humans refine their thinking mid-conversation.
With BDH, memory becomes explicit and structured. Instead of relying solely on token-based context windows and KV caches, LLMs gain a synaptic working memory that captures meaningful relationships between concepts. This memory fades naturally over time, preserving what matters while discarding noise.
Long-horizon reasoning improves dramatically under BDH. While Transformers often lose coherence as reasoning chains grow longer, BDH stabilizes thought by storing context in persistent synaptic state. This enables LLMs to plan, reflect, and reason coherently across extended interactions.
BDH also makes reasoning more interpretable. Rather than depending on post-hoc explanations, BDH exposes which conceptual connections strengthened during inference. This makes model behavior easier to understand, debug, and audit—an essential requirement in high-stakes domains.
Inference becomes more efficient as well. By remembering important information structurally rather than repeatedly passing it through tokens, BDH reduces dependence on massive context windows, lowering compute costs while improving robustness.
Another key shift is modularity. BDH allows models to be merged by combining neuron interaction graphs, avoiding catastrophic forgetting. This enables reusable, domain-specific intelligence modules instead of monolithic, retrained LLMs.
Crucially, BDH supports lifelong learning without instability. By separating short-term adaptive memory from long-term trained knowledge, LLMs can learn continuously without overwriting what they already know.
For agentic systems, this is transformative. BDH-powered LLMs can run longer, learn from mistakes immediately, and adapt strategies mid-task—making them far better suited for autonomous research, planning, and decision-making. In essence, BDH shifts LLMs from static pattern generators into adaptive reasoning systems—models that don’t just produce text, but understand what just happened and change how they think next.
The Future of AI with BDH
The emergence of Brain-like Dragon Hatchling (BDH) signals a meaningful shift in how artificial intelligence systems may evolve over the coming decade. Rather than pushing AI forward solely through larger datasets, bigger models, and longer context windows, BDH suggests a different trajectory—one where adaptation, memory, and reasoning are built directly into inference itself.
In a BDH-powered future, AI systems will no longer be frozen artifacts of their training data. Instead, they will behave more like living systems—learning from interaction, adjusting their internal state in real time, and refining their reasoning as situations unfold. This marks a departure from today’s “train once, deploy forever” paradigm toward continuous, controlled learning.

One of the most profound changes BDH introduces is the separation of short-term and long-term intelligence. Long-term knowledge remains stable and trained offline, while short-term synaptic memory allows models to adapt safely without overwriting what they already know. This opens the door to lifelong learning AI—systems that improve over time without catastrophic forgetting or constant retraining cycles.
BDH also reshapes the future of reasoning. As AI systems move beyond single-turn interactions into long-running agents—research assistants, planners, autonomous operators—reasoning stability becomes critical. By storing context in synaptic state rather than fragile token sequences, BDH enables AI to maintain coherence across long horizons, making extended planning and reflection practical rather than brittle.
Ultimately, BDH reframes the goal of artificial intelligence. Instead of building systems that merely predict the next token with increasing accuracy, it pushes toward systems that understand context, adapt behavior, and regulate learning over time. If Transformers defined the era of large-scale static intelligence, BDH may define the next era—adaptive, interpretable, and continuously evolving AI.
In that future, AI will no longer just respond—it will learn, reflect, and grow.
Conclusion
The Dragon Hatchling (BDH) challenges a long-standing assumption in modern AI: that learning must end before deployment begins. By reintroducing adaptation, memory, and local learning into the inference process, BDH reframes large language models not as static pattern machines, but as living reasoning systems—systems that can adjust, remember, and regulate themselves while they operate.
Rather than replacing Transformers outright, BDH complements and extends them. It preserves the scalability and performance that made Transformers successful, while addressing their deepest limitations: brittle long-horizon reasoning, opaque decision-making, and the inability to learn from experience. By placing memory in synapses, enabling inference-time learning, and enforcing stability through sparsity and decay, BDH offers a principled path toward models that reason more like brains and less like calculators.
Perhaps most importantly, BDH points toward a future where AI systems can be predictable, interpretable, and continuously improving—not by endless retraining, but by design. If Transformers marked the era of powerful static intelligence, the Dragon Hatchling signals the beginning of adaptive intelligence: models that don’t just generate outputs, but understand what just happened and evolve how they think next.
In that sense, BDH is not merely a new architecture—it is a new direction for AI itself.



Comments